修改這一堂的範例,計算「每個人」、「每個分工項目」統計排班的次數,並加上排名
SELECT CleanSchedule_CountResult.FamilyName,
CleanSchedule_CountResult.ItemName,
CleanSchedule_CountResult.Count_Number,
RANK() OVER (ORDER BY CleanSchedule_CountResult.Count_Number DESC) AS CountNumber
FROM (
SELECT DISTINCT
Family.FamilyName,
CleanItemList.ItemName,
COUNT(CleanSchedule.CleanItem) OVER (PARTITION BY Family.FamilyName, CleanItemList.ItemName) AS Count_Number
FROM family
INNER JOIN CleanItemList
ON 1 = 1
LEFT JOIN CleanSchedule
ON Family.FamilyID = CleanSchedule.FamilyId AND
CleanItemList.CleanItem = CleanSchedule.CleanItem
) AS CleanSchedule_CountResult
| FamilyName | ItemName | Count_Number | Rank |
|---|---|---|---|
| 泰賢 | 打掃 | 4 | 1 |
| 泰熱 | 拖地 | 4 | 1 |
| 泰肝 | 洗碗 | 4 | 1 |
| 泰賢 | 拖地 | 3 | 4 |
| 泰瘦 | 倒垃圾 | 3 | 4 |
| 泰肝 | 倒垃圾 | 3 | 4 |
| 泰冷 | 拖地 | 3 | 4 |
| 泰瘦 | 洗碗 | 3 | 4 |
| 泰胖 | 洗碗 | 3 | 4 |
| 泰熱 | 打掃 | 3 | 4 |
| 泰熱 | 倒垃圾 | 2 | 1 |
| 泰熱 | 倒垃圾 | 2 | 11 |
| 泰胖 | 打掃 | 2 | 11 |
| 泰胖 | 倒垃圾 | 2 | 11 |
| 泰冷 | 打掃 | 2 | 11 |
| 泰賢 | 洗碗 | 2 | 11 |
| 泰冷 | 倒垃圾 | 2 | 11 |
| 泰肝 | 打掃 | 1 | 17 |
| 泰熱 | 洗碗 | 1 | 17 |
| 泰賢 | 倒垃圾 | 1 | 17 |
| 泰瘦 | 拖地 | 1 | 17 |
| 泰肝 | 拖地 | 1 | 17 |
| 泰瘦 | 打掃 | 1 | 17 |
| 泰胖 | 拖地 | 1 | 17 |
| 泰冷 | 洗碗 | 0 | 24 |
1. 產生每個人、每個工作項目的清單
將每個人跟每個打掃項目,透過JOIN ON 1 = 1 的關聯方式產生
SELECT *
FROM Family
INNER JOIN CleanItemList
ON 1 = 1
| FamilyName | ItemName |
|---|---|
| 泰肝 | 打掃 |
| 泰肝 | 拖地 |
| 泰肝 | 洗碗 |
| 泰肝 | 倒垃圾 |
| 泰熱 | 打掃 |
| 泰熱 | 拖地 |
| 泰熱 | 洗碗 |
| 泰熱 | 倒垃圾 |
| 泰胖 | 打掃 |
| 泰胖 | 拖地 |
| 泰胖 | 洗碗 |
| 泰胖 | 倒垃圾 |
| 泰瘦 | 打掃 |
| 泰瘦 | 拖地 |
| 泰瘦 | 洗碗 |
| 泰瘦 | 倒垃圾 |
| 泰冷 | 打掃 |
| 泰冷 | 拖地 |
| 泰冷 | 洗碗 |
| 泰冷 | 倒垃圾 |
| 泰賢 | 打掃 |
| 泰賢 | 拖地 |
| 泰賢 | 洗碗 |
| 泰賢 | 倒垃圾 |
2. 使用Count函數計算每個人的分工次數
在Count函數後方,透過OVER子句的PARTITION BY,先將資料依照「成員ID」、「負責項目」進行分類,計算每個人在每個分工的排班次數分配
SELECT DISTINCT
Family.FamilyName,
CleanItemList.ItemName,
COUNT(CleanSchedule.CleanItem) OVER (PARTITION BY Family.FamilyId, CleanItemList.ItemName) AS Count_Number
FROM family
INNER JOIN CleanItemList
ON 1 = 1
LEFT JOIN CleanSchedule
ON Family.FamilyID = CleanSchedule.FamilyId AND
CleanItemList.CleanItem = CleanSchedule.CleanItem
| FamilyName | ItemName | Count_Number |
|---|---|---|
| 泰肝 | 倒垃圾 | 3 |
| 泰肝 | 打掃 | 1 |
| 泰肝 | 拖地 | 1 |
| 泰肝 | 洗碗 | 4 |
| 泰熱 | 倒垃圾 | 2 |
| 泰熱 | 打掃 | 3 |
| 泰熱 | 拖地 | 4 |
| 泰熱 | 洗碗 | 1 |
| 泰胖 | 倒垃圾 | 2 |
| 泰胖 | 打掃 | 2 |
| 泰胖 | 拖地 | 1 |
| 泰胖 | 洗碗 | 3 |
| 泰瘦 | 倒垃圾 | 3 |
| 泰瘦 | 打掃 | 1 |
| 泰瘦 | 拖地 | 1 |
| 泰瘦 | 洗碗 | 3 |
| 泰冷 | 倒垃圾 | 2 |
| 泰冷 | 打掃 | 2 |
| 泰冷 | 拖地 | 3 |
| 泰冷 | 洗碗 | 0 |
| 泰賢 | 倒垃圾 | 1 |
| 泰賢 | 打掃 | 4 |
| 泰賢 | 拖地 | 3 |
| 泰賢 | 洗碗 | 2 |
3.將子查詢統計出來的排班次數,透過Rank 函數進行排名的處理
在Rank 函數後方,透過OVER子句的ORDER BY,將資料依照排班次數多到排班次數少的進行排序後,給予1、2、3等等排名
SELECT CleanSchedule_CountResult.FamilyName,
CleanSchedule_CountResult.ItemName,
CleanSchedule_CountResult.Count_Number,
RANK() OVER (ORDER BY CleanSchedule_CountResult.Count_Number DESC) AS CountNumber
FROM (
SELECT DISTINCT
Family.FamilyName,
CleanItemList.ItemName,
COUNT(CleanSchedule.CleanItem) OVER (PARTITION BY Family.FamilyId, CleanItemList.ItemName) AS Count_Number
FROM family
INNER JOIN CleanItemList
ON 1 = 1
LEFT JOIN CleanSchedule
ON Family.FamilyID = CleanSchedule.FamilyId AND
CleanItemList.CleanItem = CleanSchedule.CleanItem
) AS CleanSchedule_CountResult
| FamilyName | ItemName | Count_Number | Rank |
|---|---|---|---|
| 泰賢 | 打掃 | 4 | 1 |
| 泰熱 | 拖地 | 4 | 1 |
| 泰肝 | 洗碗 | 4 | 1 |
| 泰賢 | 拖地 | 3 | 4 |
| 泰瘦 | 倒垃圾 | 3 | 4 |
| 泰肝 | 倒垃圾 | 3 | 4 |
| 泰冷 | 拖地 | 3 | 4 |
| 泰瘦 | 洗碗 | 3 | 4 |
| 泰胖 | 洗碗 | 3 | 4 |
| 泰熱 | 打掃 | 3 | 4 |
| 泰熱 | 倒垃圾 | 2 | 1 |
| 泰熱 | 倒垃圾 | 2 | 11 |
| 泰胖 | 打掃 | 2 | 11 |
| 泰胖 | 倒垃圾 | 2 | 11 |
| 泰冷 | 打掃 | 2 | 11 |
| 泰賢 | 洗碗 | 2 | 11 |
| 泰冷 | 倒垃圾 | 2 | 11 |
| 泰肝 | 打掃 | 1 | 17 |
| 泰熱 | 洗碗 | 1 | 17 |
| 泰賢 | 倒垃圾 | 1 | 17 |
| 泰瘦 | 拖地 | 1 | 17 |
| 泰肝 | 拖地 | 1 | 17 |
| 泰瘦 | 打掃 | 1 | 17 |
| 泰胖 | 拖地 | 1 | 17 |
| 泰冷 | 洗碗 | 0 | 24 |
藉由上方的結果可以發現
因為有三個相同的排班次數4排在前面,所以3個會並列第1名
排班次數第二高的3的名次會遞延到「第4名」開始
如果希望名次不要遞延,可以使用DENSE_RANK()函數
| FamilyName | ItemName | Count_Number | Rank |
|---|---|---|---|
| 泰熱 | 拖地 | 4 | 1 |
| 泰肝 | 洗碗 | 4 | 1 |
| 泰賢 | 打掃 | 4 | 1 |
| 泰胖 | 洗碗 | 3 | 2 |
| 泰瘦 | 洗碗 | 3 | 2 |
| 泰熱 | 打掃 | 3 | 2 |
| 泰肝 | 倒垃圾 | 3 | 2 |
| 泰冷 | 拖地 | 3 | 2 |
| 泰賢 | 拖地 | 3 | 2 |
| 泰瘦 | 倒垃圾 | 3 | 2 |
| 泰賢 | 洗碗 | 2 | 3 |
| 泰胖 | 打掃 | 2 | 3 |
| 泰熱 | 倒垃圾 | 2 | 3 |
| 泰胖 | 倒垃圾 | 2 | 3 |
| 泰冷 | 打掃 | 2 | 3 |
| 泰冷 | 倒垃圾 | 2 | 3 |
| 泰賢 | 倒垃圾 | 1 | 4 |
| 泰肝 | 打掃 | 1 | 4 |
| 泰胖 | 拖地 | 1 | 4 |
| 泰瘦 | 拖地 | 1 | 4 |
| 泰瘦 | 打掃 | 1 | 4 |
| 泰熱 | 洗碗 | 1 | 4 |
| 泰肝 | 拖地 | 1 | 4 |
| 泰冷 | 洗碗 | 0 | 5 |
https://www.w3schools.com/sql/trymysql.asp?filename=trysql_func_mysql_cast
找出所有國家位於「德國(Germany)」的供應商與客戶
SELECT 'Customer' As Type, ContactName, City, Country
FROM Customers
WHERE Country = 'Germany'
UNION
SELECT 'Supplier' As Type, ContactName, City, Country
FROM Suppliers
WHERE Country = 'Germany'
| Type | ContactName | City | Country |
|---|---|---|---|
| Customer | Alexander Feuer | Leipzig | Germany |
| Customer | Hanna Moos | Mannheim | Germany |
| Customer | Henriette Pfalzheim | K闤n | Germany |
| Customer | Horst Kloss | Cunewalde | Germany |
| Customer | Karin Josephs | M?ster | Germany |
| Customer | Maria Anders | Berlin | Germany |
| Customer | Peter Franken | M?chen | Germany |
| Customer | Philip Cramer | Brandenburg | Germany |
| Customer | Renate Messner | Frankfurt a.M. | Germany |
| Customer | Rita M悤ler | Stuttgart | Germany |
| Customer | Sven Ottlieb | Aachen | Germany |
| Supplier | Martin Bein | Frankfurt | Germany |
| Supplier | Petra Winkler | Berlin | Germany |
| Supplier | Sven Petersen | Cuxhaven | Germany |
以範例的「供應商」和「客戶」為例
這兩張資料表的欄位除了「CustomerID」、「SupplierID」、「CustomerName」和「Supplier」不一樣之外
都有「ContactName」、「Address」、「City」、「PostalCode」、「Country」這五個欄位
像這樣子的情境,來自不同資料來源,但結構相同的查詢
可以使用UNION 查詢
1.UNION:資料來源A的查詢結果 合併 資料來源B的查詢結果,過濾掉兩邊重複的結果
SELECT 資料來源A.欄位1, 資料來源A.欄位2, 資料來源A.欄位3 ... 資料來源A.欄位N
FROM 資料來源A
UNION
SELECT 資料來源B.欄位1, 資料來源B.欄位2, 資料來源B.欄位3 ... 資料來源B.欄位N
FROM 資料來源B
2.UNION ALL:資料來源A的查詢結果 合併 資料來源B的查詢結果,不要過濾掉兩邊重複的結果
SELECT 資料來源A.欄位1, 資料來源A.欄位2, 資料來源A.欄位3 ... 資料來源A.欄位N
FROM 資料來源A
UNION ALL
SELECT 資料來源B.欄位1, 資料來源B.欄位2, 資料來源B.欄位3 ... 資料來源B.欄位N
FROM 資料來源B
錯誤範例:
SELECT 'Customer' As Type, ContactName
FROM Customers
WHERE Country = 'Germany'
UNION
SELECT 'Supplier' As Type, ContactName, City, Country
FROM Suppliers
WHERE Country = 'Germany'
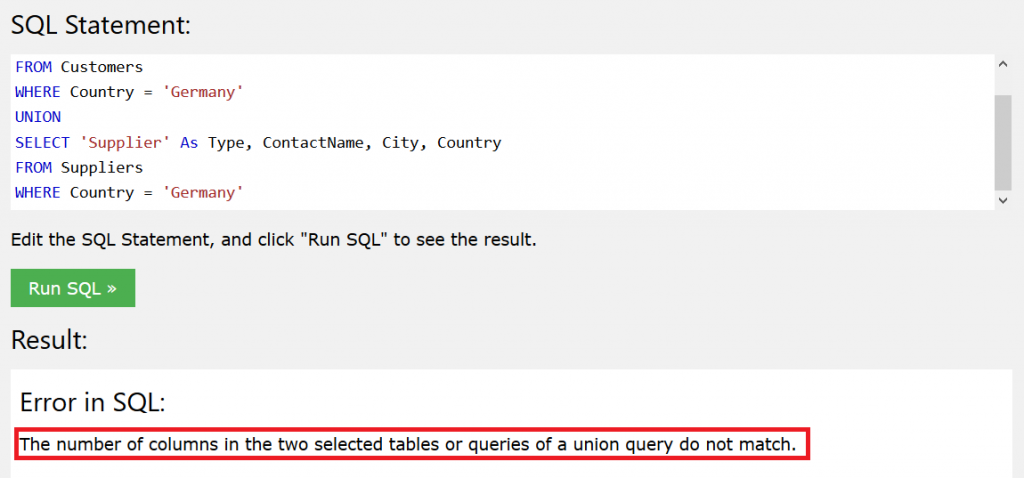
錯誤原因:
兩邊查詢欄位數量不一致
Customers的SELECT查詢有「Type」跟「ContactName」2個欄位
Suppliers的SELECT查詢有「Type」、「ContactName」、「City」「 Country」4個欄位
SELECT BirthDate
FROM Employees
UNION
SELECT SupplierName
FROM Suppliers
在網址或自己的資料庫系統測試後
會發現BirthDate是DateTime,SupplierName是Varchar
卻可以UNION,是因為DBMS幫我們把兩者全部轉換成Varchar做聯集
正確範例:
SELECT 'Customer' As Type, ContactName, City, Country
FROM Customers
WHERE Country = 'Germany'
UNION
SELECT 'Supplier' As Type, ContactName, City, Country
FROM Suppliers
WHERE Country = 'Germany'
ORDER BY ContactName
錯誤範例:
SELECT 'Customer' As Type, ContactName, City, Country
FROM Customers
WHERE Country = 'Germany'
ORDER BY ContactName
UNION
SELECT 'Supplier' As Type, ContactName, City, Country
FROM Suppliers
WHERE Country = 'Germany'
ORDER BY ContactName
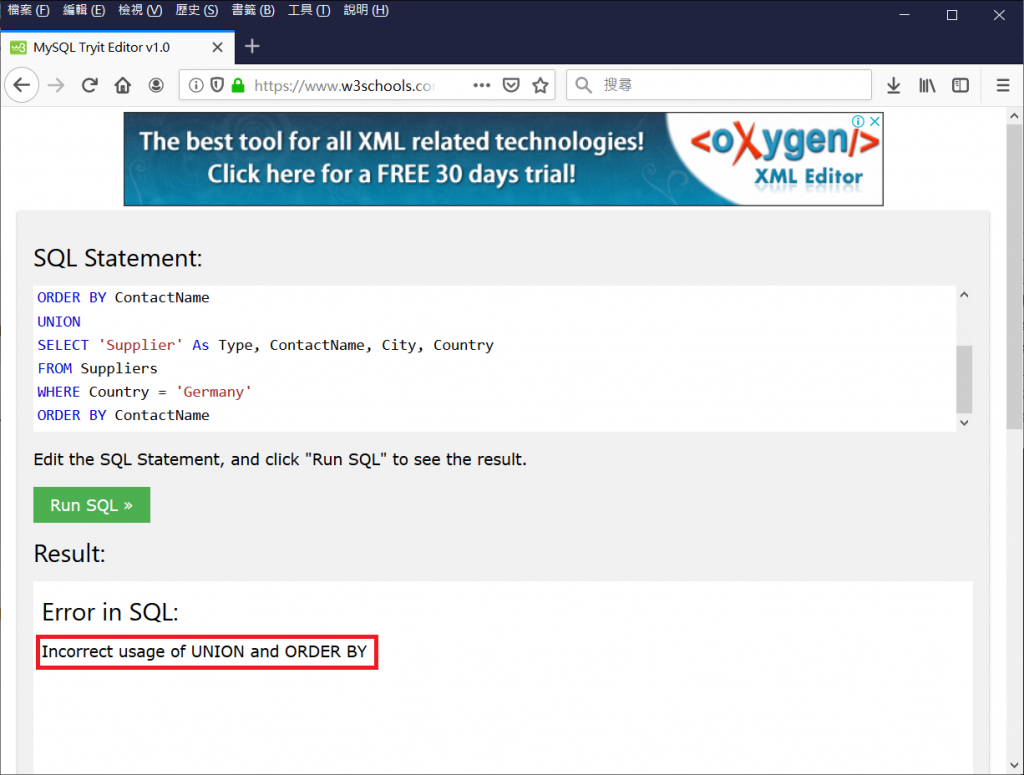
錯誤原因:
Order By 出現在UNION 聯集查詢的兩邊。
例如:幫我查詢國家位於「德國」的客戶與供應商的「城市」和「家鄉」
由於位於德國的客戶和應商,都有City = Berlin 和 Country = Germany
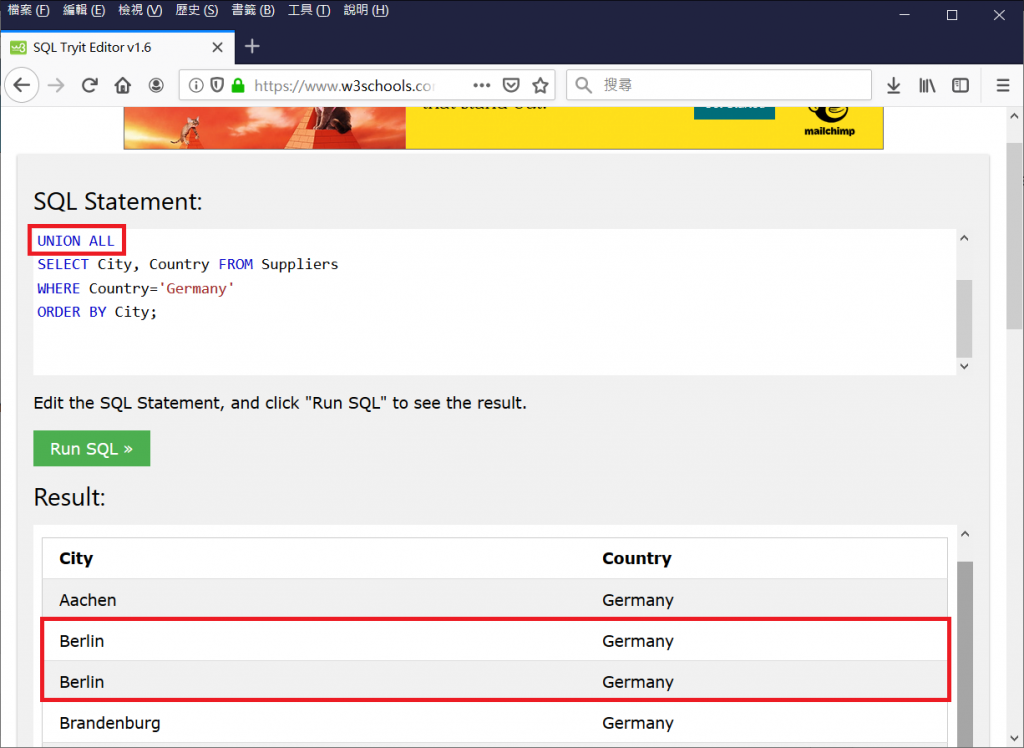
如果希望聯集完後不要有重複的資料,在UNION後方不要加上ALL。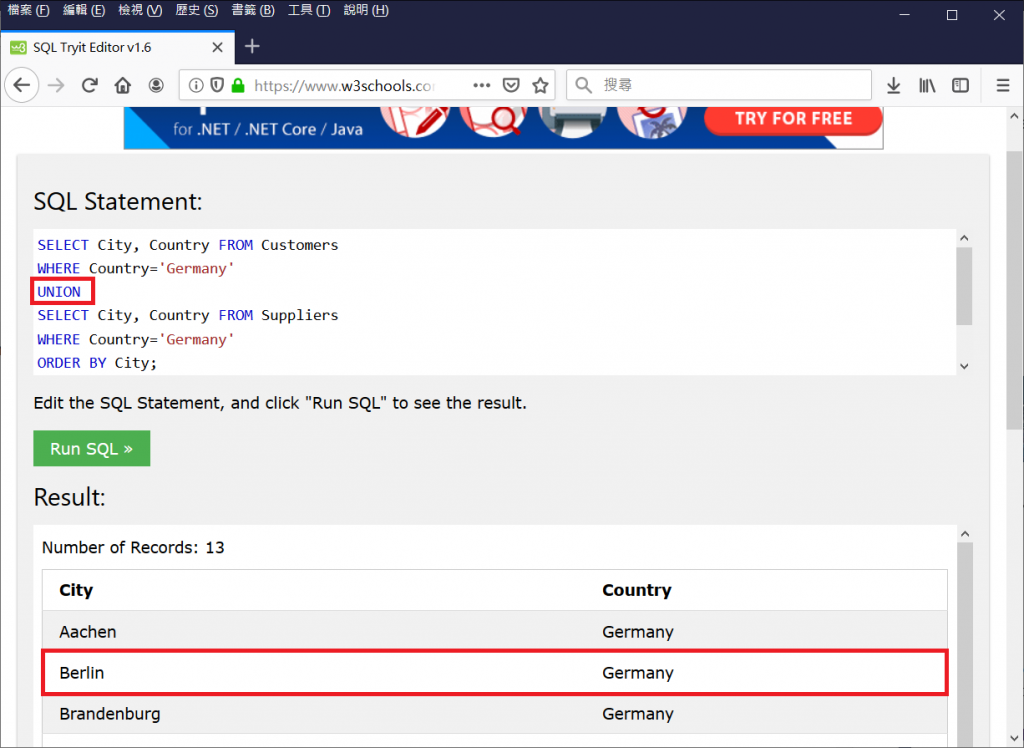
SELECT 區塊除了顯示來自所有查詢來源的資料
還可以自行給予一個字串,定義一個額外的欄位
以這堂的課堂的範例為例:
Customer的聯集查詢,自行定義一個Type欄位,內容是Customer
Suppliers的聯集查詢,自行定義一個Type欄位,內容是Supplier
https://www.w3resource.com/sql-exercises/union/sql-union-exercise-4.php
請根據「業務」與「訂單」兩張資料表,統計每一天業績最高與業績最低的業務,與業務訂單量
需列出的欄位
| ord_date | name | category | count |
|---|---|---|---|
| 2012-04-25 | James Hoog | HIGHEST | 3045.60 |
| 2012-04-25 | James Hoog | LOWEST | 3045.60 |
| 2012-06-27 | Nail Knite | HIGHEST | 250.45 |
| 2012-06-27 | Nail Knite | LOWEST | 250.45 |
| 2012-07-27 | James Hoog | HIGHEST | 2400.60 |
| 2012-07-27 | James Hoog | LOWEST | 2400.60 |
| 2012-08-17 | Lauson Hen | HIGHEST | 110.50 |
| 2012-08-17 | Paul Adam | LOWEST | 75.29 |
| 2012-09-10 | James Hoog | HIGHEST | 5760.00 |
| 2012-09-10 | Pit Alex | LOWEST | 270.65 |
| 2012-10-05 | Nail Knite | HIGHEST | 150.50 |
| 2012-10-05 | James Hoog | LOWEST | 65.26 |
| 2012-10-10 | Lauson Hen | HIGHEST | 2480.40 |
| 2012-10-10 | Mc Lyon | LOWEST | 1983.43 |
1.這題是原本題目的變化題,答案與原題目不同
2.在此網站,UNION後方的查詢請使用()包起來,例如:
SELECT XXX
FROM A
UNION (
SELECT XXX
FROM B
)


 iThome鐵人賽
iThome鐵人賽